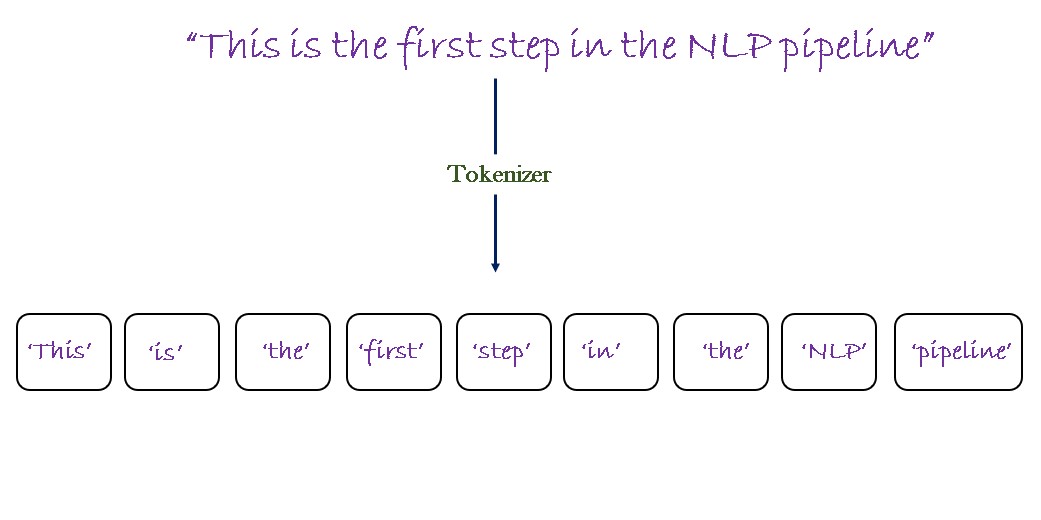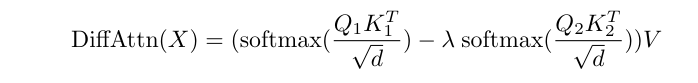
Understanding Differential Attention.
Introduction Over the last few years, Transformers have emerged as the de-facto deep learning architecture in modelling language. Their unprecendented success in solving complex language tasks, reasoning (or mimmicking it), solving math and coding problems, have ushered in a new era in AI, powering successful AI products like ChatGPT. The key innovation of transformers lies in the self-attention mechanism, which allows each tokens in the input sequence to attend to every other token in the sequence. ...