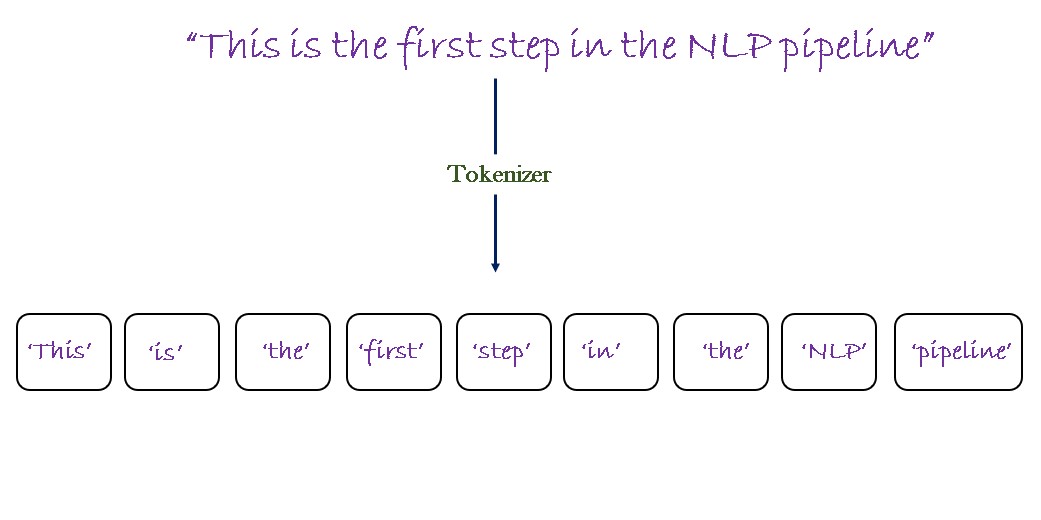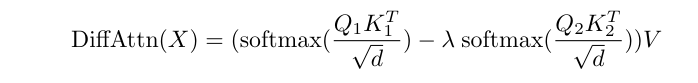
Cut Cross Entropy: 20x Memory reduction in LLM training through optimized cross entropy kernels
Introduction 2024 saw the first 100m$+ training runs, while the insane compute requirements of training Large Language Models is no secret, this jump brought more attention to the need to find tricks and methods to optimize both the transformers architecture and the training process (infrastructure). The biggest / most successful of these optimizations in recent times has been flash attention (cite here), an idea that focuses on how the compute hungry (O(N)^2) self attention mechanism is computed, by moving attention matrices to SRAM. (Essentially the idea here is that we tried to optimize self attention by modifying how the operation is performed on the GPU.). The trend of squeezing out performance as much as possible from the training infrastructure continued, with researchers writing their own optimal cuda kernels. Deepseek took this a step further, writing their own distributed file system (Fire Flyer FileSystem), a new attention mechanism (MultiHead Latent Attention with custom kernels), a highly tuned communication library for mixture-of-experts models (Deep-EP), and Deep Gemm, an FP-8 optimized matrix multiplication kernel library. ...